
래퍼 클래스란?(Wrapper Class)?
자바의 자료형은 크게 기본 타입(primitive type)과 참조 타입(reference type)으로 나누어진다.
대표적으로 기본 타입은 char, int, float, double, boolean 등이 있고 참조 타입은 class, interface 등이 있는데 프로그래밍을 하다 보면 기본 타입의 데이터를 객체로 표현해야 하는 경우가 종종 있다. 이럴 때에 기본 자료타입(primitive type)을 객체로 다루기 위해서 사용하는 클래스들을 래퍼 클래스(wrapper class)라고 한다.
자바는 모든 기본타입(primitive type)은 값을 갖는 객체를 생성할 수 있습니다.
이런 객체를 포장 객체라고도 하는데 그 이유는 기본 타입의 값을 내부에 두고 포장하기 때문이다.
래퍼 클래스로 감싸고 있는 기본 타입 값은 외부에서 변경할 수 없다. 만약 값을 변경하고 싶다면 새로운 포장 객체를 만들어야 한다.
래퍼 클래스의 종류
| 기본 타입(primitive type) | 래퍼 클래스(wrapper class) |
| byte | Byte |
| char | Character |
| int | Integer |
| float | Float |
| double | Double |
| boolean | Boolean |
| long | Long |
| short | Short |
래퍼 클래스는 java.lang 패키지에 포함되어 있는데, 다음과 같이 기본 타입에 대응되는 래퍼 클래스들이 있다.
char타입과 int타입이 각각 Character와 Integer의 래퍼 클래스를 가지고 있고 나머지는 기본 타입의 첫 글자를 대문자로 바꾼 이름을 가지고 있다.
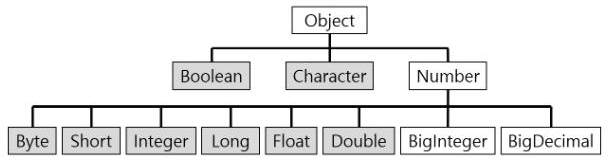
위의 계층 구조에서 볼 수 있듯 모든 래퍼 클래스의 부모는 Object이고 내부적으로 숫자를 다루는 래퍼클래스의 부모 클래스는 Number 클래스. 모든 래퍼 클래스는 최종 클래스로 정의된다.
박싱(Boxing)과 언박싱(UnBoxing)
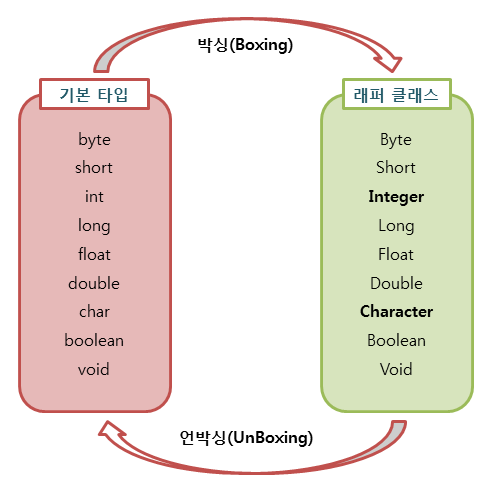
기본 타입의 값을 포장 객체로 만드는 과정을 박싱이라고 하고 반대로 포장객체에서 기본타입의 값을 얻어내는 과정을 언박싱이라고 한다.
public class Wrapper_Ex {
public static void main(String[] args) {
Integer num = new Integer(17); // 박싱
int n = num.intValue(); //언박싱
System.out.println(n);
}
}
자동 박싱(AutoBoxing)과 자동 언박싱(AutoUnBoxing)
기본타입 값을 직접 박싱, 언박싱하지 않아도 자동적으로 박싱과 언박싱이 일어나는 경우가 있다. 자동 박싱의 포장 클래스 타입에 기본값이 대입될 경우에 발생. 예를 들어 int타입의 값을 Integer클래스 변수에 대입하면 자동 박싱이 일어나 힙 영역에 Integer객체가 생성.
public class Wrapper_Ex {
public static void main(String[] args) {
Integer num = 17; // 자동 박싱
int n = num; //자동 언박싱
System.out.println(n);
}
}래퍼 클래스 간단한 사용 예제 (문자열을 기본 타입 값으로 변환)
public class Wrapper_Ex {
public static void main(String[] args) {
String str = "10";
String str2 = "10.5";
String str3 = "true";
byte b = Byte.parseByte(str);
int i = Integer.parseInt(str);
short s = Short.parseShort(str);
long l = Long.parseLong(str);
float f = Float.parseFloat(str2);
double d = Double.parseDouble(str2);
boolean bool = Boolean.parseBoolean(str3);
System.out.println("문자열 byte값 변환 : "+b);
System.out.println("문자열 int값 변환 : "+i);
System.out.println("문자열 short값 변환 : "+s);
System.out.println("문자열 long값 변환 : "+l);
System.out.println("문자열 float값 변환 : "+f);
System.out.println("문자열 double값 변환 : "+d);
System.out.println("문자열 boolean값 변환 : "+bool);
}
}출력값:
문자열 byte값 변환 : 10
문자열 int값 변환 : 10
문자열 short값 변환 : 10
문자열 long값 변환 : 10
문자열 float값 변환 : 10.5
문자열 double값 변환 : 10.5
문자열 boolean값 변환 : true
래퍼 클래스의 주요 용도는 기본 타입의 값을 박싱 해서 포장 객체로 만드는 것이지만, 문자열을 기본 타입 값으로 변환할 때에도 사용. 대부분의 래퍼 클래스에는 parse + 기본 타입명으로 되어있는 정적 메서드가 있다. 이 메서드는 문자열을 매개 값으로 받아 기본 타입 값으로 변환.
값 비교
public class Wrapper_Ex {
public static void main(String[] args) {
Integer num = new Integer(10); //래퍼 클래스1
Integer num2 = new Integer(10); //래퍼 클래스2
int i = 10; //기본타입
System.out.println("래퍼클래스 == 기본타입 : " + (num == i)); //true
System.out.println("래퍼클래스.equals(기본타입) : " + num.equals(i)); //true
System.out.println("래퍼클래스 == 래퍼클래스 : " + (num == num2)); //false
System.out.println("래퍼클래스.equals(래퍼클래스) : " + num.equals(num2)); //true
}
}래퍼클래스 == 기본타입 : true
래퍼클래스.equals(기본타입) : true
래퍼클래스 == 래퍼클래스 : false
래퍼클래스.equals(래퍼클래스) : true
래퍼 객체는 내부의 값을 비교하기 위해 == 연산자를 사용할 수 없다.
이 연산자는 내부의 값을 비교하는 것이 아니라 래퍼 객체의 참조 주소를 비교하기 때문.
비교 대상인 래퍼는 객체이므로 서로의 참조 주소가 다르다.
객체끼리의 비교를 하려면 내부의 값만 얻어 비교해야 하기에 equals를 사용해야 한다. 래퍼 클래스와 기본자료형과의 비교는 == 연산과 equals연산 모두 가능. 그 이유는 컴파일러가 자동으로 오토박싱과 언박싱을 해주기 때문!!
그렇다면 Wrapper Class를 사용했을때. 즉! Wrapping을 했을때 얻게 되는 이점은 무엇이 있을까?
Collection을 Wrapping 하면서, 그 외 다른 멤버 변수가 없는 상태를 일급 컬렉션이라고 한다.
일급 컬렉션은 객체지향적으로 리팩토링하기 쉬운 코드로 가기 위해 필요한 부분이라고 한다.
일급 콜렉션의 사용조건을 살펴보면, 이 규칙의 적용은 간단하다. 콜렉션을 포함한 클래스는 반드시 다른 멤버 변수가 없어야하며, 각 콜렉션은 그 자체로 포장되 있으므로 이제 콜렉션과 관련된 동작은 근거지가 마련된셈이다.
필터가 이 새 클래스의 일부가 됨을 알 수 있고, 필터는 또한 스스로 함수 객체가 될 수 있다. 또한 새 클래스는 두 그룹을 같이 묶는다든가 그룹의 각 원소에 규칙을 적용하는 등의 동작을 처리 할 수 있다. 이는 인스턴스 변수에 대한 규칙의 확실한 확장이지만 그 자체를 위해서도 중요한 부분이다.
간단하게 살펴보자면, 아래의 코드를
Map<String, String> map = new HashMap<>();
map.put("1", "A");
map.put("2", "B");
map.put("3", "C");
아래와 같이 Wrapping 하는 것을 말함
public class GameRanking {
private Map<String, String> ranks;
public GameRanking(Map<String, String> ranks) {
this.ranks = ranks;
}
}위에서도 언급했지만 이처럼 Collection을 Wrapping 하면서, 그 외 다른 멤버 변수가 없는 상태를 일급 컬렉션이라 부른다.
Wrapping을 하게 될 경우 다음과 같은 이점을 가지게 된다.
- 비즈니스에 종속적인 자료구조
- Collection의 불변성을 보장
- 상태와 행위를 한 곳에서 관리
- 이름이 있는 컬렉션
1. 비즈니스에 종속적인 자료구조
예를 들어 다음과 같은 조건으로 로또 게임을 만든다고 가정을 해보면, 이 게임은 다음과 같은 조건이 있다.
- 6개의 번호가 존재(이번 예제에서 보너스 번호는 제외)
- 6개의 번호는 서로 중복되지 않아야함.
일반적으로 이런 경우는 서비스 메소드에서 진행을 한다. 이것을 구현해보면,
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class LottoService {
public static final int LOTTO_NUMBERS_SIZE = 6;
public void createLottoNumber() {
List<Long> lottoNumbers = createNonDuplicateNumbers();
validateSize(lottoNumbers);
validateDuplicate(lottoNumbers);
// 이후 로직 쭉쭉 실행
}
private void validateSize(List<Long> lottoNumbers) {
if(lottoNumbers.size() != LOTTO_NUMBERS_SIZE) {
throw new IllegalArgumentException("로또 번호는 6개만 가능");
}
}
private void validateDuplicate(List<Long> lottoNumbers) {
Set<Long> nonDuplicateNumbers = new HashSet<>(lottoNumbers);
if(nonDuplicateNumbers.size() != LOTTO_NUMBERS_SIZE) {
throw new IllegalArgumentException("로또 번호들은 중복될 수 없다.");
}
}
}이렇게 서비스 메소드에서 비즈니스 로직으로 처리가 가능하다. 이런 경우에는 문제가 발생된다. 로또 번호가 필요한 모든 장소에선 검증로직이 들어가야하기 때문이다.
문제 예시
- List<Long>으로 된 데이터는 모두 검증 로직이 필요한가?
- 신규 입사자분들은 어떻게 이 검증로직이 필요한지 알 수 있을까?
기타 등등 모든 코드와 도메인을 알고 있지 않다면 언제든 문제가 발생 할 수 있다. 이러한 문제를 해결하기 위해선 6개의 숫자로만 이루어져야만하고, 서로 중복되지 않아야하는 자료구조를 만들어야한다.
해당 조건으로 생성 할 수 있는 자료구조를 만들게되면 위에서 언급한 문제들을 해결 할 수 있다. 이러한 과정을 해결하기위해 적용되는 클래스를 우리는 일급 컬렉션이라고 부르고 있다.
public class LottoService {
public static final int LOTTO_NUMBERS_SIZE = 6;
private final List<Long> lottoNumbers;
public LottoTicket(List<Long> lottoNumbers) {
validateSize(lottoNumbers);
validateDuplicate(lottoNumbers);
this.lottoNumbers = lottoNumbers;
}
// 6개 / 중복되지 않은 숫자들만 가능한 자료구조
private void validateSize(List<Long> lottoNumbers) {
if(lottoNumbers.size() != LOTTO_NUMBERS_SIZE) {
throw new IllegalArgumentException("로또 번호는 6개만 가능");
}
}
private void validateDuplicate(List<Long> lottoNumbers) {
Set<Long> nonDuplicateNumbers = new HashSet<>(lottoNumbers);
if(nonDuplicateNumbers.size() != LOTTO_NUMBERS_SIZE) {
throw new IllegalArgumentException("로또 번호들은 중복될 수 없다.");
}
}
}이제 로또 번호가 필요한 모든 로직은 이 일급 컬렌션만 있으면 됨.
public class LottoService2 {
public void createLottoNumber() {
LottoTicket lottoTicket = new LottoTicket(createNonDuplicateNumbers()); //필요한 로직은 모두 LottoTicket으로
//이후 로직 쭉쭉 실행
}이렇게 비즈니스에 종속적인 자료구조가 만들어져, 이후 발생할 문제를 최소화 할 수 있었다.
2. 불변
일급 컬렉션은 컬렉션의 불변을 보장한다. final의 경우가 있지만 Java의 final은 정확하게는 불변을 만들어주는 것은 아니며, 재할당만 금지를 한다. 아래 코드를 살펴보면,
@Test
public void final도_값변경이_가능하다() {
//given
final Map<String, Boolean> collection = new HashMap<>();
//when
collection.put("1", true);
collection.put("2", true);
collection.put("3", true);
collection.put("4", true);
//then
assertThat(collection.size()).isEqualTo(4);
}이를 실행해보면
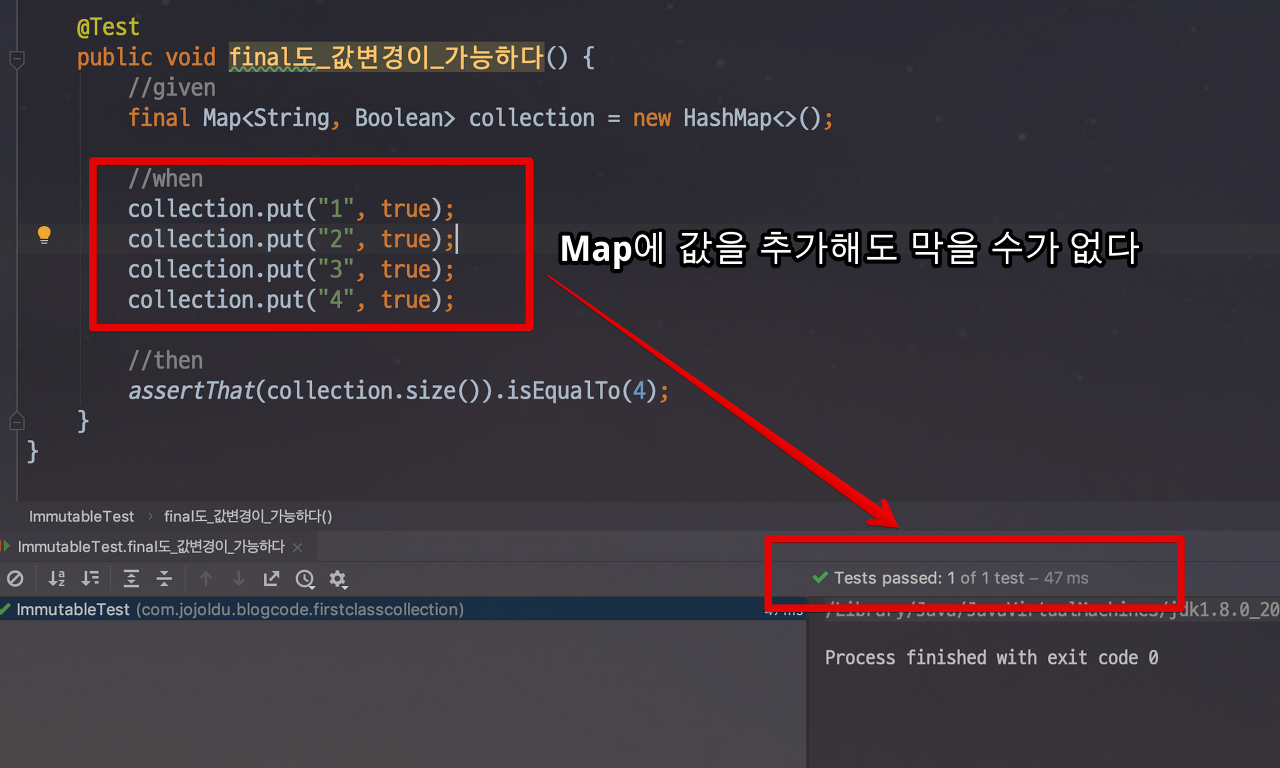
값이 추가되는 부분을 파악 할 수 있다. 이미 컬렉션은 비어있는 HashMap을 선언했음에도 불구하고 값이 변경 될 수 있다.
추가적인 테스트를 진행해보자면,
@Test
public void final은_재할당이_불가능하다() {
//given
final Map<String, Boolean> collection = new HashMap<>();
//when
collection = new HashMap<>();
//then
assertThat(collection.size()).isEqualTo(4);
}이 코드는 바로 컴파일에러가 발생한다.
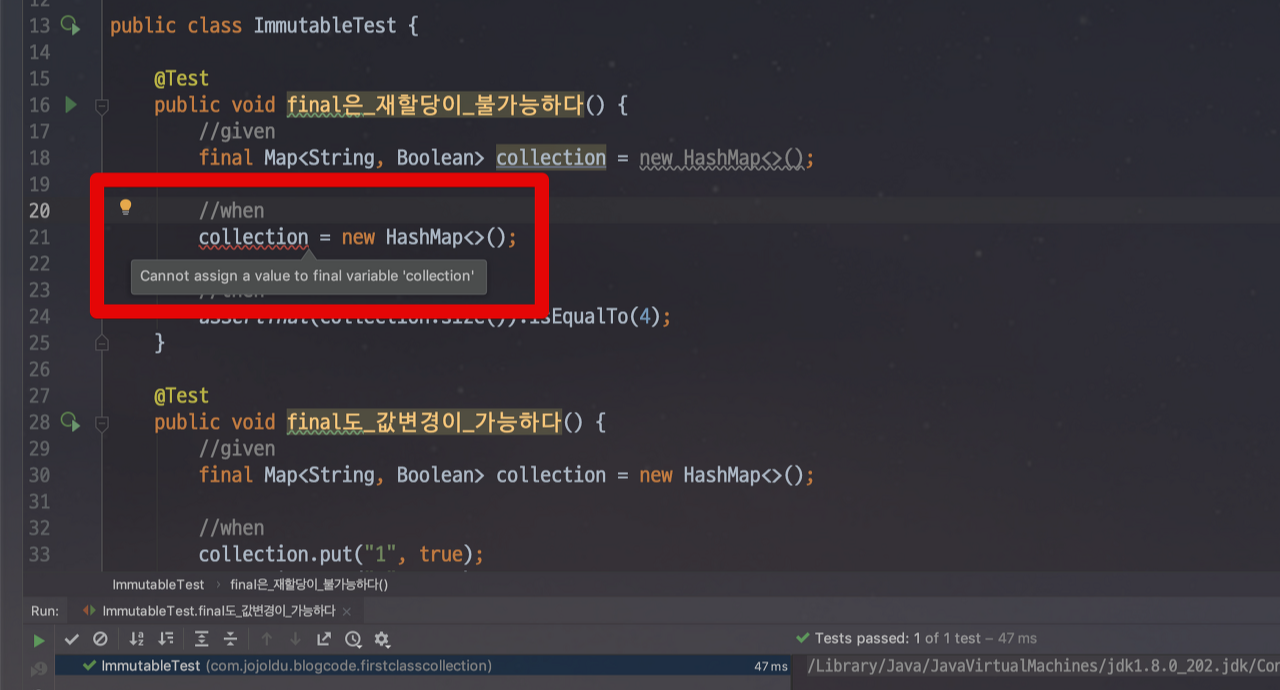
final로 할당된 코드에 재할당을 할 수 없기 때문이다. Java의 final은 재할당만 금지를 한다. 요즘 같이 소프트웨어의 규모가 커지고 있는 시점에 불변 객체는 아주 중요하다고한다. 각각의 객체들이 절대 값이 바뀔일이 없다는것이 보장이 되면 그만큼 코드를 이해하고 수정하는데 사이드 이펙트가 최소화되기 때문이다.
Java에서는 final로 그 문제를 해결 할 수 없기에 일급 컬렉션(First Class Collection)과 래퍼 클래스(Wrapper Class) 등의 방법으로 해결 을 할 수 있다.
아래 코드처럼 컬렉션의 값을 변경할 수 있는 메소드가 없는 컬렉션을 만들어내면 불편 컬렉션이 된다.

이 클래스는 생성자와 getAmountSum() 외에 다른 메소드가 없다. 즉, 이 클래스의 사용법은 새로 만들거나 값을 가져오는것뿐이다. List라는 컬렉션에 접근할 수 있는 방법이 없기 때문에 값을 변경하거나 추가를 할 수 없다.
이런 경우 일급 컬렉션을 사용하게 되면, 불편 컬렉션을 만들 수 있다.
3. 상태와 행위를 한곳에서 관리
일급 컬렉션의 또 다른 장점은 값과 고직이 함께 존재한다는것이다. 이 부분은 Java의 Enum과도 비슷한 부분이다. 예를들어 여러 Pay들이 모여 있고, 이 중 NaverPay 금액의 합이 필요하다고 가정을 해보면,
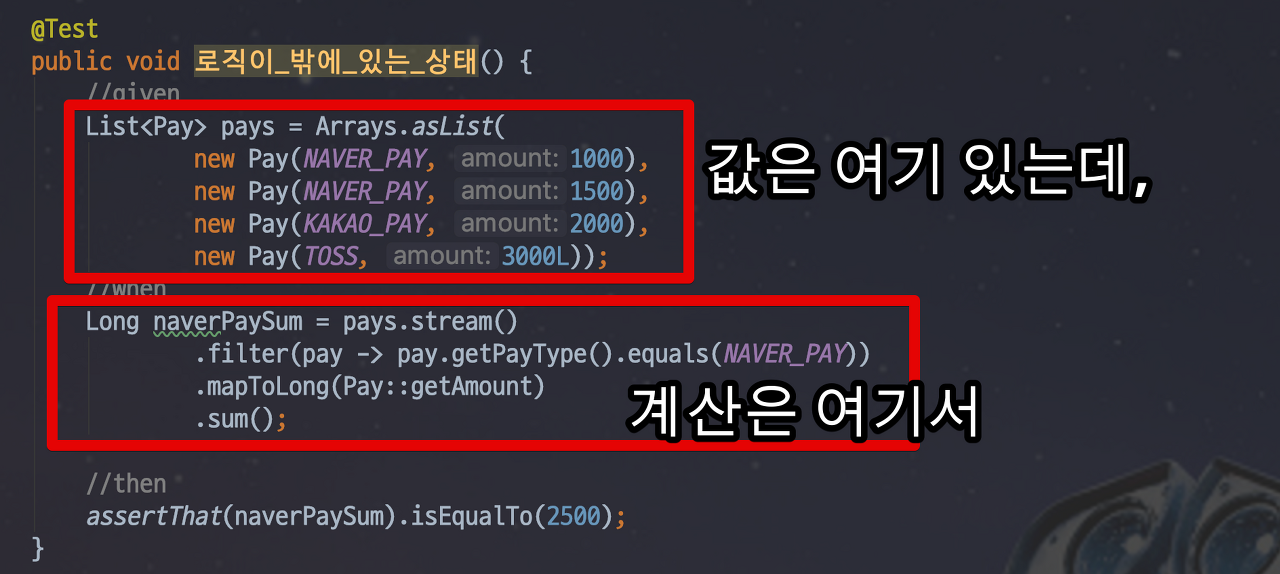
일반적으로 List에 데이터를 담고, Service 혹은 Util 클래스에서 필요한 로직을 수행한다.
이럴경우 pays라는 컬렉션과 계산 로직은 서로 관계가 있는데, 이를 코드로 표현이 안된다. pay 타입의 상태에 따라 지정된 메소드에서만 계산되길 원하는데, 현재 상태로는 강제 할 수 있는 수단이 없다. 지금은 Pay타입의 List라면 사용 될 수 있기때문에 히스토리를 모르는 경우라면 실수 할 여지가 많다고한다.
똑같은 기능을 하는 메소드를 중복 생성할 가능성이 있다.
히스토리가 관리 안된 상태에서 신규화면이 추가되어야 할 경우 계산 메소드가 있다는것을 몰라 다시 만드는 경우가 빈번하게 발생될 수 있다. 만약 기존 화면의 계산 로직이 변경 될 경우, 신규 인력은 2개의 메소드의 로직을 다 변경해야하는지, 해당 화면만 변경해야하는지 알 수 없다. 또한 관리 포인트가 증가할 확률이 매우 높다.
계산 메소드를 누락 할 수도 있는데, return 받고자하는 것이 Long 타입의 값이기 때문에 꼭 이 계산식을 사용해야한다고 강조를 할 수 없다.
결국엔 네이버페이 총 금액을 뽑을려면 이렇게 해야한다는 계산식을 컬렉션과 함께 두어야한다. 만약 네이버페이 외에 카카오 페이의 총금액도 필요하다면 코드가 더욱 흩어질 확률이 높다. 이러한 경우도 역시 일급 컬렉션으로 해결 할 수 있다.
public class PayGroups {
private List<Pay> pays;
public PayGroups(List<Pay> pays) {
this.pays = pays;
}
public Long getNaverPaySum() {
return pays.stream()
.filter(pay -> PayType.isNaverPay(pay.getPayType()))
.mapToLong(Pay::getAmount)
.sum();
}
}만약 다른 결제 수단들의 합이 필요하다면 아래와 같이 람다식으로 리팩토링 가능하다.
public class PayGroups {
private List<Pay> pays;
public PayGroups(List<Pay> pays) {
this.pays = pays;
}
public Long getNaverPaySum() {
return getFilteredPays(pay -> PayType.isNaverPay(pay.getPayType()));
}
public Long getKakaoPaySum() {
return getFilteredPays(pay -> PayType.isKakaoPay(pay.getPayType()));
}
private Long getFilteredPays(Predicate<Pay> predicate) {
return pays.stream()
.filter(predicate)
.mapToLong(Pay::getAmount)
.sum();
}
}이렇게 PayGroups 이라는 일급 컬렉션이 생김으로 상태와 로직이 한곳에서 관리 된다.
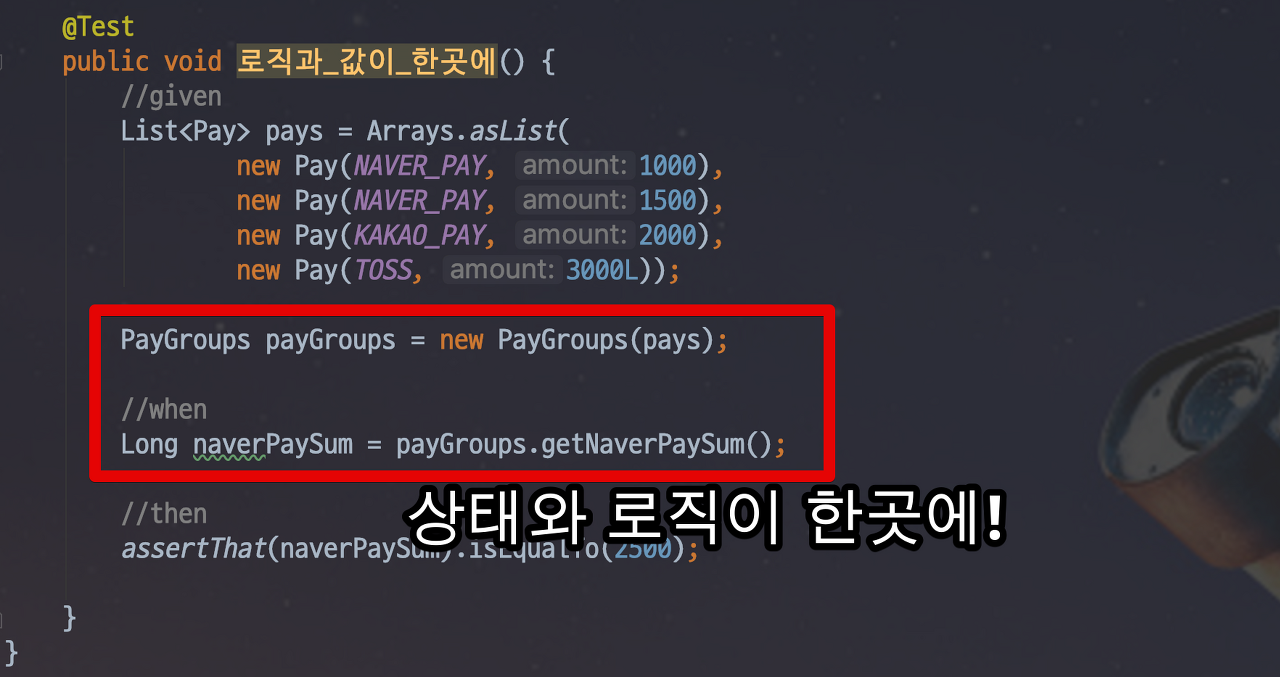
4. 이름이 있는 컬렉션
마지막 장점은 컬렉션에 이름을 붙일 수 있다는 것이다. 같은 Pay들의 모임이지만 네이버페이의 List와 카카오페이의 List는 다르다. 이 둘을 구분하려면 어떻게 해야할까? 가장 흔한 방법은 바로 변수명을 다르게 하는 것이다.

위 코드의 단점은 일단 검색이 어렵다.
네이어 페이 그룹이 어떻게 사용되는지 검색 시 변수명으로만 검색 할 수 있고, 이 상황에서 검색은 거의 불가능하다. 네이버페이의 그룹이라는 뜻은 개발자마다 다르게 지을 수 있기 때문이다.
또한 명확한 표현이 불가능하다. 변수명에 불과하기 때문에 의미를 부여하는게 어렵다. 이는 개발팀/운영팀간에 의사소통시 보편적인 언어로 사용하기가 어려움을 이야기하기도한다. 중요한것임에도 이를 표현할 명확한 단어가 없게 되는것이다.
이럴경우 역시나 컬렉션으로 쉽게 해결이 가능하다. 네이버페이 그룹과 카카오페이 그룹 각각의 일급 컬렉션을 만들면 이 컬렉션 기반으로 용어사용과 검색을 하면 된다.
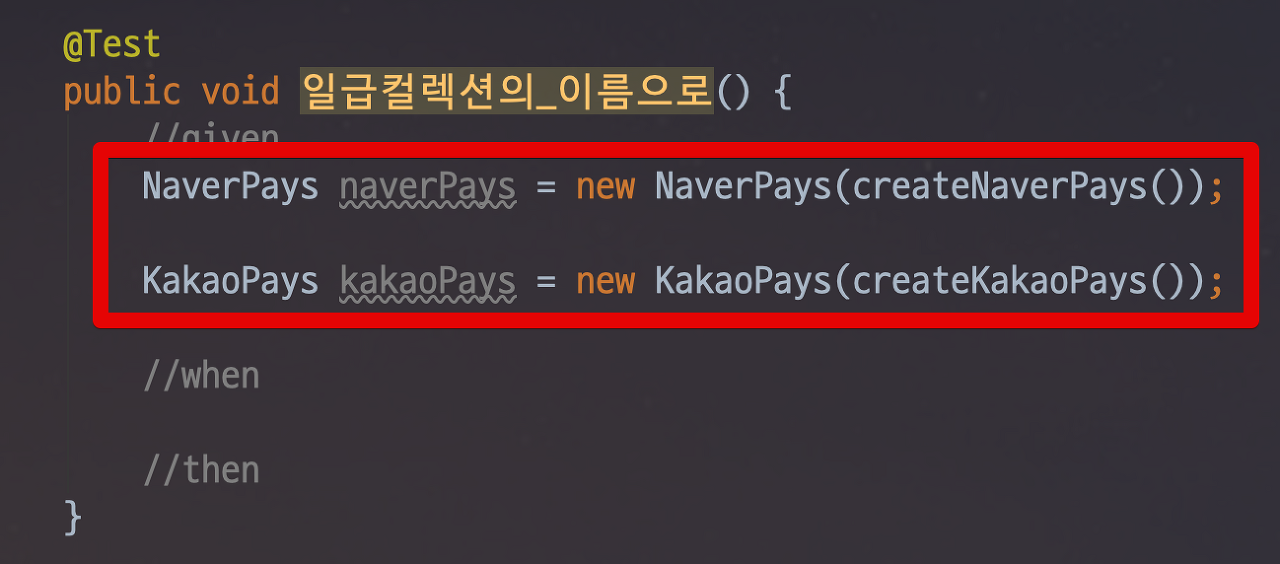
개발 및 운영팀 내에서 사용될 표현은 이제 이 컬렉션에 맞추면 된다. 검색 역시 이 컬렉션 클래스를 검색하면 모든 사용 코드를 찾아 낼 수 있다.
코딩팩토리와 향로님 블로그를 참고하여 래퍼 클래스와 사용목적 및 일급컬렉션에 대해 적어놨는데, 아직 이해하기엔 나에겐 많이 어렵다.
Enum과 마찬가지로 객체지향코드로 접근하기위해서 일급 컬렉션을 익히는것이 좋다는데, 아직 내 머릿속으로는 잘 돌아가지가 않는다. 필요한 이유를 다시 생각해보면서 나중에 실제 프로젝트에서도 한 번 적용을 해봐야겠다.
하나 하나 알아간다는 재미도 있지만, 하나 하나 배울때마다 남들보다 뒤처진다는 느낌은 어쩔수가 없구나..ㅠㅜ
멘탈 관리 역시 나에게 필요한 부분..
출처
: https://coding-factory.tistory.com/547
: https://jojoldu.tistory.com/412?category=635881
'JAVA' 카테고리의 다른 글
| [Java] JVM 구조에 대한 설명. 그리고 버전에 따라 무엇이 바뀌는가? (0) | 2022.02.22 |
|---|---|
| [Java] 백준 별 찍기 2438번 2439번 2440번 (0) | 2022.02.22 |
| [Java] Stream & Lambda 람다 스트림 (0) | 2022.01.28 |
| [Java] HashMap (0) | 2022.01.26 |
| [Java] StringTokenizer hasMoreTokens() nextToken() (0) | 2022.01.24 |