
스트림(Stream)과 람다(Lambda)는 Java 8부터 추가된 API다. 교육을 받던 시기 람다에 대해서 잠깐 언급만하고 넘어갔었고, 아직까지 업무하면서 제대로 사용해본적은 없지만, 공부에는 끝이 없는지라 예제를 통해 어떤 녀석들인지 알아보기로 한다.
Lambda
먼저 람다부터 살펴보면
class Calculator {
Calculator() {};
public int calc(int n) {
return n + 1;
};
}
class Driver {
public static void main(String[] args) {
int n = 2;
Calculator cal = new Calculator();
System.out.println(cal.calc(n)); //3
}
}Calculator 클래스는 calc() 메소드를 통해 매개변수 n을 받아 1을 증가시키고 리턴을 하게 된다. 자바의 람다는 메소드를 하나의 식(Expression)으로 표현한 것이다. 익명메소드(함수) 생성 문법이라 할 수 있는데, 메소드명이 없이 구현부로 선언을 하였다.
하지만 자바의 메소드는 메소드 자체로 혼자서만 사용 될 수가 없다. 무조건 Class 구성멤버로 선언이 되어야한다. 우리가 주로 사용하는 main() 또한 메소드 클래스 멤버이다. 다만 어플리케이션이 실행할때 JVM이 알아서 static main()을 찾아 실행시켜주는것뿐이다.
람다식을 통해 생성되는건 메소드 자체가 아닌 실행문(메소드)을 가진 객체이다. 람다식은 일반적인 객체가 아닌 인터페이스를 구현한 익명구현 객체를 생성한다.
상단의 코드에서 Calculator가 interface로 바뀐다면?
interface Calculator {
int calc(int n);
}Calculator라는 인터페이스는 calc()이라는 추상메소드를 가지게 된다. Calculator를 객체화하기 위해선 implements한 class를 생성하거나 익명 클래스로 생성하는 방법이 있다.
인터페이스는 인터페이스 자체로 구현체(객체)를 만들 수 없지만, 인터페이스의 추상 메소드를 생성과 동싱에 {}으로 감싼 곳에 @Override하여 구현 할 수 있다. 아래는 Calculator 인터페이스를 익명 클래스 방식으로 구현을 한 것이다.
class Driver {
public static void main(String[] args) {
int n = 2;
// 생성과 동시에 구현할 메소드를 override 함
Calculator cal = new Calculator() {
@Override
int calc(int n) {
return n + 1;
}
}
System.out.println(cal.calc(n)); // 3
}
}
람다식에서 생성되는 익명구현객체는 기반이 되는 interface의 타입을 가지고 있는데 이것을 타겟타입이라 부른다. 우리가 람다식으로 바꿀 메소드 calc()이므로 람다식의 타겟타입은 Calculator이다.
람다의 기본식은 (매개변수) -> {실행문}의 형태를 지니고 있다.
class Driver {
public static void main(String[] args) {
int n = 2;
// (매개변수) -> {구현로직}
Calculator cal = (int n) -> {return n + 1;};
System.out.println(cal.calc(n)); // 3
}
}기존의 코드를 람다의 기본식으로 구현하였다.
class Driver {
public static void main(String[] args) {
int n = 2;
// (매개변수) -> {구현로직}
Calculator cal = (n) -> {return n + 1;};
System.out.println(cal.calc(n)); // 3
}
}위 코드는 매개변수의 타입을 자동으로 인식하기 때문에 변수 타입을 삭제 할 수 있다.
class Driver {
public static void main(String[] args) {
int n = 2;
// (매개변수) -> {구현로직}
Calculator cal = n -> {return n + 1;};
// 매개변수가 없는 경우 무조건 ()가 필요함. () -> {return "hi";}
System.out.println(cal.calc(n)); // 3
}
}매개변수가 하나 일때는 ()을 생략 할 수 있다. 두 개이상 혹은 없을 때는 () 가 필요하다.
class Driver {
public static void main(String[] args) {
int n = 2;
Calculator cal = n -> n + 1; // 간단하게 변경
System.out.println(cal.calc(n)); // 3
}
}로직이 한 줄안에 끝나는 경우에는 {} return을 제거하는것이 가능하다.
앞서 언급했던 타겟 타입에 대해서 살펴보자면, 컴파일러는 람다식을 해석하면 자동으로 익명구현객체로 만들게 된다. 이때 람다식의 타겟 타입이 될 인터페이스는 2개 이상의 추상 메소드를 가지면 안된다고한다. 이렇게 되면 컴파일러가 해당 람다식이 타겟 타입의 어떤 메소드를 구현한 것인지 알 수 없기때문이다.
@FuntionalInterface는 이러한 부분을 선언하고 강제적으로 하는 어노테이션이다. 이런 방법으로 선언된 인터페이스를 람다식의 함수적 인터페이스라고 부른다.
@FuntionalInterface 함수적 인터페이스 선언
@FuntionalInterface // 어노테이션을 붙히고 2개 이상의 추상메소드를 만들면 컴파일 에러가 발생한다.
interface Calculator {
int calc(int n);
int sum(int a, int b); // 에러발생
}
람다식의 매개변수는 final 키워드가 붙지 않더라도 불변하는 상수로 취급하게 된다.
class Driver {
public static void main(String[] args) {
int n = 2;
Calculator cal = n -> ++n; // 매개변수를 변경시키려 하면 에러발생
System.out.println(cal.calc(n)); // 3
}
}
이러한 람다식 활용예시를 살펴보면, 자바에서 변수 역할을 할 수 있는 것은 Primitive 타입(int, long, boolean 등), Object 타입(Object를 상속 받는 모든 것)이다. 람다식을 만들 수 있는 타겟타입도 변수가 될 수 있으므로, 람다식과 같이 활용하게 되면 메소드도 매개변수처럼 사용이 가능하다고한다.
public static void printCalc(int n, Calculator cal) {
System.out.println(cal.calc(n));
}
@FuntionalInterface
interface Calculator {
int calc(int n);
}
class Driver {
public static void main(String[] args) {
int n = 2;
// int n과 구별하기 위해 람다식에는 v라는 변수명을 사용.
printCalc(n, v -> v + 1); // n + 1, 출력값 3
printCalc(n, v -> v - 1); // n - 1, 출력값 1
printCalc(n, v -> v * 2); // n * 2, 출력값 4
}
public static void printCalc(int n, Calculator cal) {
System.out.println(cal.calc(n));
}
}
calc()와 printCalc를 변형시키지 않고 매개변수에 어떠한 람다식을 넣어주느냐에 따라 리턴되는 값들을 다르게 할 수 있다.
Stream
String 타입의 값을 Integer로 변환하기 위해서는 Integer.parseInt() 메소드를 사용하게 된다.(Buffereader 알고리즘 풀때 많이 사용해봤었지..)
아래 예제의 최종 결과값은 문자열 List에 있는 값을 더한 것이다. 그렇기때문에 List의 String값을 Integer 값으로 모두 변환하여 더해줘야한다.
Parser class의 strToIntList()메소드는 for loop를 돌며 parseInt()를 해주고 변환된 값들을 다시 List<Integer>에 담아 반환해주는 역할을 한다.
class Driver {
public static void main(String[] args) {
// 문자열 List
List<String> strList = Arrays.asList("1,2,3,4,5,6".split(","));
// 문자열 List를 Integer List로 변환
List<Integer> intList = Parser.strToIntList(strList);
int sum = 0; // 총 합
// 덧셈
for (Integer value : intList) {
sum += value;
}
System.out.println(sum); // 21
}
}class Parser {
public static List<Integer> strToIntList(List<String> strList) {
List<Integer> intList = new ArrayList<>();
for (String value : strList) {
intList.add(Integer.parseInt(value));
}
return intList;
}
}
자바의 Stream은 컬렉션(Collection)의 요소를 하나씩 참조하여 람다식으로 처리 할 수 있게해주는 일종의 반복자다. [I/O(입출력) 관련과는 아무 관련이 없음. Input/OutputStream. InputStream은 java.io 패키지, Stream은 java.util 패키지이다.]
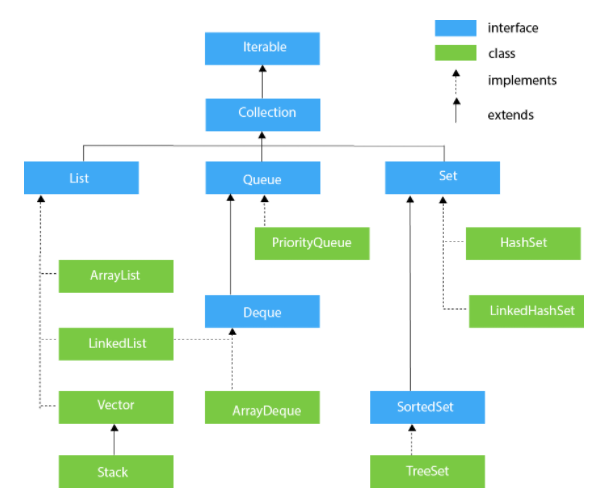
자바의 Collection 인터페이스는 Set, List, Queue 인터페이스처럼 데이터를 저장하는 자료구조들의 상위에 있는 인터페이스다. 최상위에는 iterator() 메소드를 가지고 있는 Iterable 인터페이스가 있다.
iterator()는 Iterator<T>를 반환한다. Iterator는 자료안에 자료가 있는지 없는지 확인해주는 hasNext() 메소드와, 자료구조에 저장되어 있는 자료를 하나씩 리턴해주는 next() 메소드를 가지고 있다. 즉, Collection을 implements한 모든 자료구조들은 iterarot()로 반복자를 만들어 반복문을 돌릴 수 있다.
class Driver {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,5,6);
Iterator<Integer> iter = list.iterator();
// 순서대로 1 2 3 4 5 6 출력
while (iter.hasNext()) {
System.out.println(iter.next());
}
}
}다시 스트림으로 돌아와. 상단의 Iterator를 Stream으로 변형을 해보면
class Driver {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,5,6);
// Integer 데이터를 갖는 Stream 생성
Stream<Integer> stream = list.stream();
// forEach()를 사용해서 1 2 3 4 5 6 출력
stream.forEach((Integer i) -> { System.out.println(i); });
/*
* list.stream().forEach(System.out::println);
* 메소드 레퍼런스를 사용하면 코드를 더 줄일 수 있음
*/
}
}스트림의 특징이 나오게 된다. 바로 forEach()의 매개변수로 람다식을 사용 할 수 있다.
스트림의 특징을 살펴보면, 스트림은 Collection의 반복자와 다른 특징을 몇 가지 갖는다. 변형된 예제코드를 보면서 확인해보면 일단 반복자가 있는 부분을 스트림으로 변형시켜보겠다.
class Driver {
public static void main(String[] args) {
// 문자열 List
List<String> strList = Arrays.asList("1,2,3,4,5,6".split(","));
// 문자열 List를 Integer List로 변환
List<Integer> intList = Parser.strToIntList(strList);
// 총 합
int sum = intList.stream().mapToInt(Integer::intValue).sum();
System.out.println(sum); // 21
}
}
class Parser {
public static List<Integer> strToIntList(List<String> strList) {
return strList.stream()
.map(Integer::parseInt)
.collect(Collectors.toList());
}
}이러한 형태로 람다식을 사용 할 수 있다. Stream 객체의 메소드들은 모두 람다식을 매개변수로 가질 수 있다. 람다식에서 배웠던 표준 함수적 인터페이스가 모두 포함되며, Stream의 메소드마다 각기 다른 함수적 인터페이스를 쓸 수 있으니 적용을 해보자
이제 반복자를 모두 스트림으로 변경한 코드를 보자
strList.stream().map(Integer::parseInt).collectors.toList());문자열 List를 정수형 List로 변환해주는 strToIntList()의 메소드가 한줄로 줄어들었다.
이러한 특징으로 볼때,
- Collection은 .stream()을 사용하여 Stream 타입의 객체로 바꿔줄수 있다.
- map()은 Function<T, R> 함수적 인터페이스(람다식)를 매개변수로 받아 Stream의 데이터를 하나씩 람다식으로 처리해서 다시 Stream 객체에 담는다.
- collect()는 스트림의 데이터를 모아 새로운 객체를 만들어 리턴한다. 상단의 코드에선 Collectors.toList()를 사용하여 List 객체를 만들어 리턴한다.
| 리턴 타입 | 메서드(매개변수) | 소스 |
| Stream<T> | java.util.Collection.stream() java.util.Collection.parallelStream() |
컬렉션 |
| Stream<T> IntSream LongStream DoubleStream |
Arrays.stream(T[ ]), Stream.of(T[ ]) Arrays.stream(int[ ]), IntStream.of(int[ ]) Arrays.stream(long[ ]), LongStream.of(long[ ] ) Arrays.stream(double[ ]), DoubleStream.of(double[ ] ) |
배열 |
| IntStream | IntStream.range(int, int) IntStream.rangeClosed(int, int) |
int 범위 |
| LongStream | LongStream.range(long, long) LongStream.rangeClosed(long, long) |
long 범위 |
| Stream<Path> | Files.find(Path, int, BiPredicate, FileVisitOption) Files.list(Path) |
디렉토리 |
| Stream<String> | Files.lines(Path, Charset) BufferedReader.lines( ) |
파일 |
| DoubleStream IntStream LongStream |
Random.doubles(...) Random.ints( ) Random.longs( ) |
랜덤 수 |
Stream은 객체 스트림(Stream<T>) 이외에도 기본 타입에 특화된 IntStream, LongStream, DoubleStream 등과 같은 기본 타입 스트림 라이브러리를 가지고 있다.
int sum = intList.stream().mapToInt(Integer::intValue).sum();intList에 있는 값의 총 합을 구하고 싶다면, IntStream에 스트림의 모든 값을 더 해주는 sum( )가 있기 때문에 intList를 IntStream로 바꾸어 사용한다. IntStream.of( )로 직접 생성과 초기화하여 IntStream을 만드는 방법도 있지만, mapToInt( )로 기본 스트림을 IntStream으로 바꿔 줄 수도 있다.
ex) Stream.of(“1”,”2”,”3”,”4”,”5”,”6”).stream.mapToInt(Integer::parseInt).sum(); 방식으로 String 스트림을 IntStream으로 변경해줄 수 있다.
단말연산 sum( )으로 IntStream의 모든 데이터를 더한 값을 얻는다.
스트림은 또한 중간 / 단말연산을 가지고 있다.
위에 언급된 코드를 줄여보면
Class Driver {
public static void main(String[] args) {
// 문자열 List
List<String> strList = Arrays.asList("1,2,3,4,5,6".split(",");
// 총합
int sum = strList.stream().mapToInt(Integer::parseInt).sum();
System.out.println(sum); //21
}
}스트림은 스트림을 계속 스트림을 받환하여 연산을 이어서 할 수 있게하는 중간연산과 스트림을 종료시키고 결과를 반환하는 단말연산, 두 가지 종류의 메소드를 가지고 있다.
중간연산
| 연산 | 반환값 | 연산 인수 | 함수 디스크립터 |
| filter | Stream<T> | Predicate<T> | T -> boolean |
| map | Stream<T> | Function<T, R> | T -> R |
| limit | Stream<T> | ||
| sorted | Stream<T> | Comparation<T> | (T, T) -> int |
| distinct | Stream<T> |
중간연산자들은 Stream 객체를 다시 가공해서 Stream 객체로 만드는 연산을 한다.
List<String> strList = Arrays.asList("3", "1", "4", "2", "5", "5");
strList.stream() //문자열 스트림 생성
.map(Integer::parseInt) //문자열 스트림을 정수형 스트림으로 변환
.sorted() //정렬
.distinct() //중복제거
.limit(3) // 객수를 3개로 제한
.collect(Collectors.toList()); //리스트로 변환 -> {1, 2, 3}중간 연산자들은 연속해서 사용 할 수 있고, 중간연산 이후엔 다른 스트림이 반환 된다. 원본인 strList Collection의 값들은 바뀌지 않는다.
단말연산
| 연산 | 비고 |
| forEach | 스트림에 각 요소를 람다를 통해 특정 작업을 실행한다. |
| count | 스트림의 요소 개수를 반환한다.(long) |
| collect | 스트림을 컬렉션 형태로 반환한다. |
단말연산자는 스트림을 받아 결과값을 만들고 더 이상 스트림을 반환하지 않는다.(스트림을 닫는다) 만약 여산을 계속 이어하고 싶다면 스트림을 다시 만들어 작업을 이어가야한다.
Stream.of("3", "1" ,"4", "2", "5", "5") //문자열 스트림 생성
.map(Integer::parseInt) //문자열 스트림을 정수형 스트림으로 변환
.sorted() //정렬
.distinct() //중복제거
.limit(3) //갯수를 3개로 제한
.collect(Collectors.toList()) //리스트로 변환 => {1, 2, 3}
.stream() //다시 정수형 값을 갖는 스트림으로 변환
.filter(x -> x >1) //1보다 큰 값만 갖도록 필터링함 {2, 3}
.forEach(System.out::println); //2와 3만 출력됨연산의 순서
스트림은 지연된(lazy) 연산을 한다. 단말연산이 없으면 연산을 실행하지 않고, 단말연산이 수행되기 전에 중간연산이 실행되지 않는다. 결과가 필요하기전까지는 실행되지 않는다는 뜻이다.
Stream.of("3", "1", "4", "2", "5", "5")
.map(x -> {
System.out.println("map:" + x);
return Integer.parseInt(x);
})
.filter(x -> {
System.out.println("filter:" + x);
return x > 1;
});이 코드를 실행하면 단말연산이 없기 때문에 아무것도 출력되지 않는다.
Stream.of("3", "1", "4", "2", "5", "5")
.map(x -> {
System.out.println("map:" + x);
return Integer.parseInt(x);
})
.filter(x -> {
System.out.println("filter:" + x);
return x > 1;
})
.forEach(x -> {
System.out.println("forEach:" + x);
});
//출력값
map : 3
filter : 3
forEach : 3
map : 1
filter : 1
map : 4
filter : 4
forEach : 4
map : 2
filter : 2
forEach : 2
map : 5
filter : 5
forEach : 5
map : 5
filter : 5
forEach : 5이 코드를 실행하게 되면 예상한 결과와 다른 값이 나올 것이다. 우리는 보통 스트림이 해당 연산을 처리한 후에 전체 스트림을 넘겨 다시 작업할 것이라 생각한다. map에서 전부 출력하고, filter에서 전부 출력하고 forEach에서 filter에서 걸러진 나머지 값들을 출력할 거라고 생각 할 것이다.
하지만 스트림의 요소들이 개별적으로 중간연산들을 통과해서 단말연산에 도달하는 순으로 진행이 된다. 그렇기 때문에 연산의 순서를 바꿈으로 연산이 실행되는 횟수를 줄일 수 있을것이다.
병렬처리
스트림은 parallel()을 활용하여 연산은 병렬로 처리 할 수 있다.
Stream.of("1", "2", "3", "4", "5", "5")
.filter(x -> {
System.out.println("filter:" + x);
return !x.equals("5");
})
.mapToInt(x -> {
System.out.println("map:" + x);
return Integer.parseInt(x);
})
.forEach(x -> {
System.out.println("forEach:" + x);
});위에 코드를 실행하면 결과값은 앞서 배운 연산순대로 각 인자가 순서대로 연산들을 통과하게 된다.
filter : 1
map : 1
forEach : 1
filter : 2
map : 2
forEach : 2
filter : 3
map : 3
forEach : 3
filter : 4
map : 4
forEach : 4
filter : 5
fo;ter : 5하지만 병렬 스트림으로 바꾼다면?
Stream.of("1", "2", "3", "4", "5", "5")
.parallel() //병렬스트림으로 변경
.filter(x -> {
System.out.println("filter:" + x);
return !x.equals("5");
})
.mapToInt(x -> {
System.out.println("map:" + x);
return Integer.parseInt(x);
})
.forEach(x -> {
System.out.println("forEach:" + x);
});parallel()로 스트림을 병렬 스트림으로 바꾼 뒤 연산들을 수행하면 연산은 순서없이 병렬로 처리가 된다.
filter : 2
map : 2
forEach : 2
filter : 5
filter : 5
filter : 4
filter : 1
map : 1
filter : 3
map : 3
forEach : 1
map : 4
forEach : 3
forEach : 4만약 스트림안에 데이터가 매우 많다면, 병렬 스트림과 연산의 순서를 활용하여 더 빠르게 연산 할 수 있을 것이다.
직접 따라하면서 해봤지만, 아직 완벽하게 이해하지는 못했다...조금 더 공부해보고, 참고해주신 부분을 조금 더 살펴봐야할 것같다.
'JAVA' 카테고리의 다른 글
| [Java] 백준 별 찍기 2438번 2439번 2440번 (0) | 2022.02.22 |
|---|---|
| [Java] Wraper Class 래퍼 클래스 란? (0) | 2022.02.04 |
| [Java] HashMap (0) | 2022.01.26 |
| [Java] StringTokenizer hasMoreTokens() nextToken() (0) | 2022.01.24 |
| [Java] 불필요한 객체 생성를 피하기 이펙티브 자바 new String (0) | 2022.01.21 |